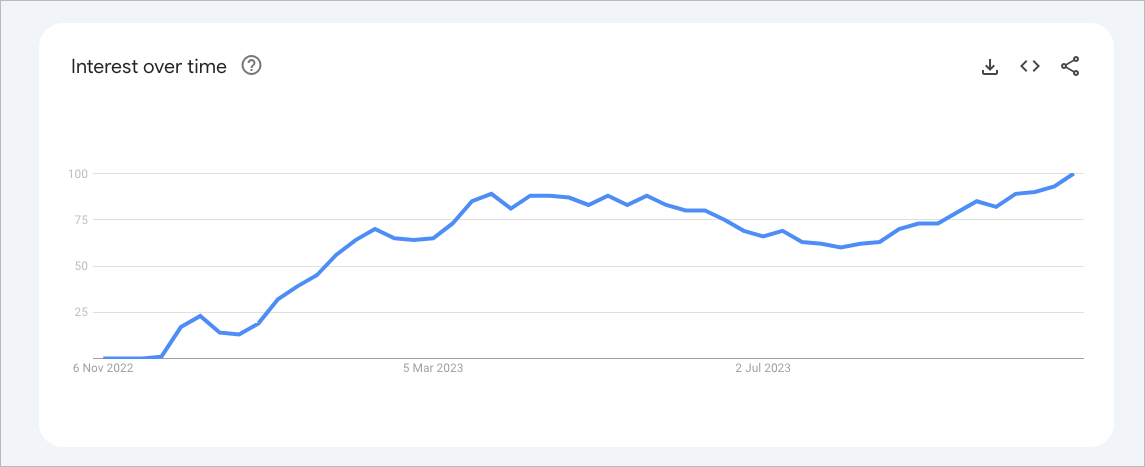
We have grown sick of social media. But what comes next?
We have had nearly two decades of it now and it’s made a lot of us unhappier.
What’s coming next could go either way. In some ways generative AI — the flavour of AI in ChatGPT and its competitors — offers us something even worse, where technology locks us in a room with ourselves. In this world generative AI just amplifies the customisation of content to monopolise our attention. The vision that most compellingly captures this is E.M. Forster’s, where in The Machine Stops (1909) humans obsess over machine-driven prompts and lose the will and capability to connect socially.

That’s not fun to think of. We know that leaving us alone with interactive technology rarely makes us better, more socialised people. We are susceptible to manipulation, we engage in a race to the lowest common denominator, we ignore our surroundings, we cannot look away.
Generative AI may well further entrench and monetise this.
Beyond the Milky Way
But there is another way: where generative AI offers us a chance to access, and contribute to, a perfect union of human and machine, allowing us to unlock the riches of human knowledge and solve some of the mysteries of our age. In this guise AI can unlock and mobilise everything that any one of us has discovered and give us insights into those things that still befuddle us: the quantum world, the extra-dimensional world, the physical world beyond our galaxies.
All this is up for grabs.
And no, I’m not lapsing into madness. Just exploring the less outlandish conclusions reached by a surprisingly well connected cohort of minds that intersect Silicon Valley government, academia, and religion. It’s best captured by Diana Walsh Pasulka in her just-published Encounters, one of the first academics to peer behind the curtain of respectability to find a hidden elite of thinkers who are ready to believe at least some of the less scientific research into extra-dimensional worlds, including those that could be from another galaxy or epoch.
This is an area to tread lightly on, for two reasons. One is that, as Pasulka puts it herself, much of ufology — the study of UFOs — is a “clown show.” You have to be careful out there. And secondly, there is a strain in Silicon Valley of elitism I would say borders on a übermensch fetish — the pursuit of a becoming a superman (for they are, mainly, men). The people Pasulka talk to are not, for the most part, of that world, but there is definitely an overlap.

Moving a muscle
Despite that, I believe this idea that GAI might unleash — and democratise — the sum of our knowledge is worth exploring. I believe it because generative AI has come at a point where we have hit a technological wall. We’re tired of social media’s narcissistic self loathing, the dumbed-down world where the loudest, crudest and cruellest mouth wins out. Where idealism — including Effective Altruism — becomes just another grift. Where our computer barely needs to move a muscle to do the things we ask of it, while at the same time vast hangers are set aside for processing the algorithms to keep us hooked on the next doom-scroll, to process the micro auction to decide who gets the privilege of flashing an ad to us, or processing the next block in a cryptocurrency transaction.
(To provide some scale, the online ad business accounted for a 10th of all energy consumption by the tech industry in 2014 (PDF; the latest year figures are available), crypto accounts for up to 0.9% of global energy usage, and social media accounts for 0.61% of the world’s CO2 impacts in 2019.)
The challenge we face, therefore, is huge. We somehow have to redirect all this computing to something worthwhile, something from which all of us can benefit. Which is why I cut those in Pasulka’s book who talk in these grandiose ways a bit more slack than I might have done previously.
While we focus inwards, they are focusing outwards, beyond the micro cents and algorithmic addictions, to something much more interesting. They see themselves as descendants of the Rosicrucians, an order of sages that combined mysticism with what we might today call science. One group called themselves the Invisible College, a term that modern-day ufologists have adopted for themselves.
I’m not a fan of this secrecy and elitism, but given the public (and academic) contempt for those who believe there might be “something out there” it does make sense. There are at least three Nobel laureates who have faced ridicule or persecution for their interest in such things.

Ripples never come back
But we don’t have to go all that way. GAI could help us unleash a new wave of learning by scaling up an under-sung contribution to learning: Youtube. This vast engine of what you might call distributed learning has gone largely unnoticed. It presents and delivers highly accessible content in a personalised format. The question is whether generative AI will magnify and scale up this learning or whether it will bypass it.
Let’s take the Youtube channel of musician Rick Beato. He has 3.8 million subscribers, who watch in live feed when he expertly breaks down a popular song to its constituent parts. A recent video on Genesis’ “Ripples” explains not only the song but the nature of chord progressions, training your ear to work out chords and melody, and on the importance of knowing music theory. He does all this while viewers pepper the chat room with comments, questions and requests.
So how would GAI impact this? On the scaling side, AI could answer the questions automatically, further personalising the delivery of information, and ultimately leading to greater and deeper specialisation as users dig further, with generative AI as a guide. In this model Beato becomes the entry point, the introduction, the inspiration for the creators themselves, quickly moving beyond Beato’s (impressive) knowledge of the subject.
Or there’s another way, where GAI bypasses this bubbling lava pool of knowledge. In this future generative AI would simply need a few pointers on what style you want your song to be, how many beats per minute, what key signature, what mood you want — and then hey presto! You have a piece of “original” content for you. This approach might well sap the desire to explore and master musicianship and to engender that heady feeling that you’re making something out of nothing — the most extraordinary human gift and achievement.
Toxic tunes
If AI can do it better than you then what motivation do you have for earning that? (This, by the way is already happening. Here’s a list of the top ‘AI music generators’ and a piece by two Andreessen Horowitz partners, whose vision is exactly as I described above: “Our ultimate dream? An end-to-end tool where you provide guidance on the vibe and themes of the track you’re looking to create, in the form of text, audio, images, or even video, and an AI copilot then collaborates with you to write and produce the song.”)
Almost certainly, both sides will find a way to stay in the game. But whereas we can still argue that social media was just an aberration, a failure on our part to figure out a non-toxic balance between addiction, privacy, business models and community, we shouldn’t just assume that things will be different this time. There is huge profits to be made from our social media addiction, and so we shouldn’t assume the same interests will be trying to prevail this time.
While I’m sure it’s a little idealistic to dream this way, I do think there’s a possible future that involves a hyper-personalised world of knowledge and betterment, without the isolation, mental health issues, and general troll-like toxicity.
The chances are greater if we’re paying attention.